
Advance pediatric care using Amazon HealthLake for scalable FHIR-based data analytics
Article courtesy of Amazon Web Service Blog, published December 19, 2022
Blog is guest authored by Meen Chul Kim from Children’s Hospital at Philadelphia

The ability to quickly and securely share data is a critical success factor for researchers around the world working to find cures for childhood illnesses. Recognizing an opportunity to accelerate this important work, Children’s Hospital of Philadelphia (CHOP) partnered with Amazon HealthLake (HealthLake) to provide their researchers with a Fast Healthcare Interoperability Resources (FHIR)-based data platform capable of supporting a scalable and low maintenance solution for clinical research.
Introduction
The Center for Data Driven Discovery in Biomedicine (D³b) at CHOP provides personalized care for children through collaborative, data-driven science. The multidisciplinary team at D³b combines basic science, translational research, precision medicine, bioinformatics and genomic research to target pediatric cancers and rare diseases of childhood development, including pediatric brain tumors. To accelerate their work, the team at D³b needed better ways to:
- Collaborate with other research centers around the globe.
- Securely collect, analyze, and visualize large volumes of clinical and genomic data collected over the lifetime of a patient’s treatment plan.
- Manage and maintain data systems so staff can focus on the data itself not the data infrastructure.
The D³b team partnered with the Amazon Web Services (AWS) Health AI team to pilot Amazon HealthLake with enhanced analytics feature. The focus of the pilot was to explore new HealthLake capabilities that transform medical data into an analytics-ready format in near real-time from multiple sources using the industry standard FHIR R4 format. This enables querying, visualizing, and building of machine learning models using a wide range of AWS services.
This blog post describes some key challenges research centers commonly face when trying to share data at scale, and how CHOP implemented a pilot program using HealthLake to address those challenges.
Key challenges
The D³b team recognized that adopting a well-supported standard was essential to their goal of sharing data from a wide range of sources. FHIR was selected because it is widely recognized as a healthcare interoperability standard to describe and exchange clinical data. However, it presented inherent limitations that needed to be overcome.
First, data formats natively supported by FHIR are XML and JSON, which are highly nested/structured. Due to the complex nature of these data formats, it is less intuitive to navigate the FHIR resources.
Second, it presents consumption challenges for downstream workflows such as querying resources, data warehousing, and statistical analysis, due to its nested structure, as compared to traditional tabular data structures.
Third, there are ever-growing needs for data reporting and advanced data analytics for a variety of clinical and research use cases. Example scenarios include data entry QC, patient view dashboard, cohort building, biobanking, and more. However, traditional dashboarding tools lack capabilities to tabulate FHIR resources and make them quick to query, analyze, and visualize at scale.
Amazon HealthLake provides capabilities to address these challenges while leveraging the inherent strengths of FHIR R4 data format.
Solution architecture
To overcome the challenges described above, and promote collaboration with other research centers, D³b team partnered with the AWS Health AI team to test the new analytics feature of Amazon HealthLake. They built a data platform solution that enabled automatic ingestion, storage, and extraction of FHIR resources using Amazon HealthLake and the natively embedded machine learning (ML) service Amazon Comprehend Medical. This allows end users to run standard Structured Query Language (SQL) queries against the FHIR resources with Amazon Athena, and build data analytics products using AWS analytical services, such as Amazon QuickSight and Amazon SageMaker.
To ensure the pilot was conducted under real-world conditions the D³b team used data sets from three current research projects:
- Children’s Brain Tumor Network (CBTN).
- The Gabriella Miller Kids First Pediatric Research Program (Kids First)
- The INvestigation of Co-occurring conditions across the Lifespan to Understand Down syndromE Project (INCLUDE)
The following diagram describes the solutions architecture that was implemented for this pilot. The architecture leverages AWS native services to offer a fully managed solution that aligns with AWS’ Well Architected framework. The Well Architected framework ensures solutions built on AWS are optimized for security, performance, reliability, and cost.
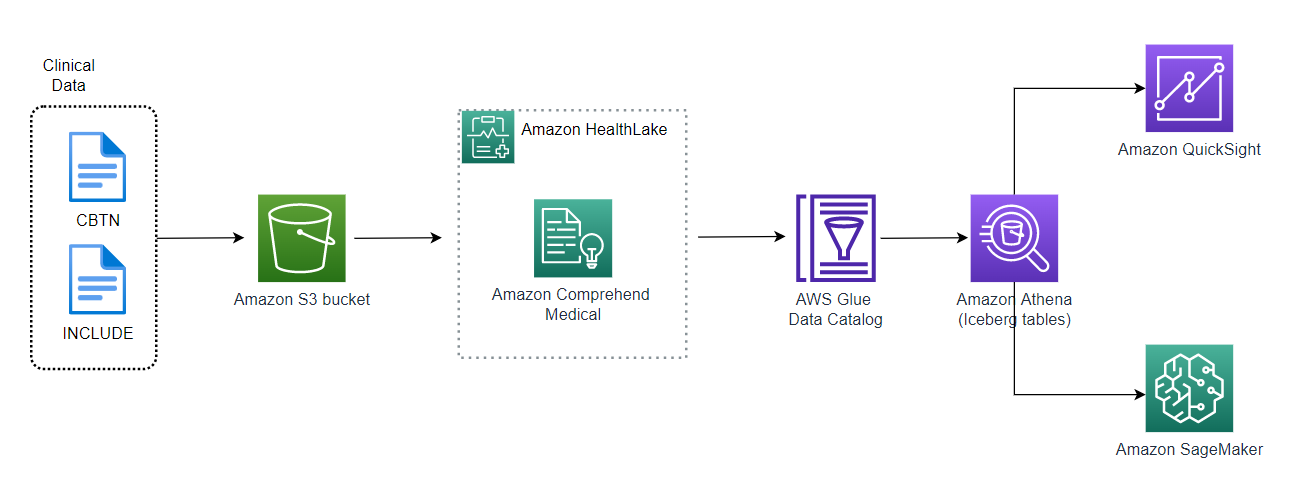
Figure 1 – Data Platform Solution Architecture for CHOP Pilot
The following are the processes and benefits of the data platform solution the D³b team built in collaboration with AWS.
Amazon HealthLake
The core of the solution is Amazon HealthLake (HealthLake), which is a HIPAA-eligible service to securely store and enable analytics of health data at petabyte scale for healthcare and life sciences organizations. With the enhanced analytics feature, HealthLake can transform customer data into an analytics-ready format in near real-time. This eliminates the need for customers to stage data in separate data stores, execute complex data exports, and perform custom data transformations. It has the benefits of cost saving, reduced data processing time, and reduced management overhead. Customers can quickly deploy a health data platform that is scalable and promotes efficient data sharing through an interoperable standard―FHIR.
The D³b team first followed the FHIR Bulk Data Access protocol to bulk-export FHIR resources from CBTN, Kids First, and INCLUDE data sets, and used pagination to organize the FHIR resources by endpoints (for example, /Patient, /specimen). Then these FHIR resource data files were uploaded to an Amazon Simple Storage Service (Amazon S3) bucket by using AWS SDK enabling them to be imported into HealthLake data stores.
The team then used HealthLake import API to load the FHIR data files from Amazon S3 into a HealthLake data store. After importing the data, HealthLake uses natively embedded ML service Amazon Comprehend Medical to automatically understand and extract clinically relevant information from the imported Document Reference resources of the imported data sets.
HealthLake organizes and indexes all the information and stores it in FHIR R4 format. This enables a complete view of each patient’s medical history. The D³b team was then able to utilize HealthLake APIs to query against HealthLake data store to perform Create/Read/Update/Delete (CRUD) and FHIR Search operations.
Amazon Athena
Amazon Athena (Athena) is an interactive query service that enables analysis of data stored in data lakes using standard SQL. Athena scales automatically (executing queries in parallel) so results are fast, even with large datasets and complex queries. Athena promotes ad hoc querying and analysis of data without the need for complex Extract, Transform, Load (ETL) transformations and relational databases.
With the enhanced HealthLake analytics feature, data schemas of FHIR resources stored in HealthLake are automatically created in AWS Glue Data Catalog as database, tables, and columns. Every FHIR resource type is turned into a distinct table, and all FHIR JSON attributes are separated as columns. This decouples the transactional FHIR APIs in HealthLake from the reporting and analytics layer. Through native integration with Athena, the database and tables are then made available for SQL-based data analysis. All these activities are performed in the background without the need for users to intervene.
With these new features offered by HealthLake and native integration with Athena, the D³b team was able to ingest the CBTN, Kids First, and INCLUDE data sets into a HealthLake data store. They then were able to perform complex data analysis using SQL. They were also able to save Athena query results for downstream applications to visualize and perform analytics on the data sets.
Amazon QuickSight
Amazon QuickSight (QuickSight), a cloud-native serverless business intelligence service, enables users to create and share dashboards that can be embedded into any application to add interactive analytics. One of the data sources natively supported by QuickSight is Amazon Athena. With a 1-click process, the database and HealthLake data in Athena can be connected to QuickSight.
The D³b team configured QuickSight to connect to Athena tables. With this connection, they were able to reference the patient cohort data stored inside Amazon HealthLake and build visual dashboards in QuickSight. Furthermore, leveraging the QuickSight Embedded feature, the D³b team is working on customizing and embedding QuickSight dashboards into a web interface application that supports visualization of the FHIR resources. This implementation greatly minimizes the maintenance overhead for the D³b team. Instead of having to maintain REACT web applications to develop dashboards and visuals, they were able to leverage QuickSight’s low-code environment to quickly build and maintain visual dashboards.
Amazon SageMaker
Amazon SageMaker (SageMaker) is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly build and train machine learning models. The models can then be directly deployed into a production-ready hosted environment. The Jupyter notebook feature in SageMaker can integrate with Athena and populate data frames to facilitate data manipulation operations.
As a next step for this work, the D³b team plans to utilize the Jupyter notebooks in SageMaker to connect to the Athena tables. The data scientists will then be able to query the CBTN, Kids First, and INCLUDE data sets stored in HealthLake and enable machine learning based analytics.
Outcomes
The pilot data platform solution demonstrated that researchers on the D³b team can:
- Reliably exchange diverse clinical data sets at scale with other researchers and research centers through a process that is secure, complaint, and auditable.
- Leverage interoperability standards to remove data integration barriers between disparate health care systems and data formats.
- Overcome the inherent limitations of utilizing FHIR data for analytics, by representing FHIR resources as common tabular data.
- Quickly query data to perform advanced analytics and build powerful visualizations using familiar SQL and common reporting tools.
- Eliminate the management and maintenance overhead of on-premises infrastructure and simplify the creation of end-user dashboards.
Conclusion
Enabling the exchange of clinical data and medical information in a consistent and interoperable way is a challenge healthcare organizations are trying to solve. Currently, implementing an interoperable data store that also promotes efficient analytics is a challenging task, which requires overcoming barriers related to cost, complexity, and management overhead.
The D³b team at CHOP partnered with the AWS Health AI team to leverage new analytics capabilities in HealthLake, and created a scalable, quick-to-deploy, FHIR-enabled data platform solution. This solution removed barriers, optimized cost, and accelerated clinical research collaboration with other healthcare institutions.
The cloud-based data platform also removed the burden and undifferentiated heavy lifting associated with on-premises data systems. It enabled the D³b team to quickly perform large-scale analysis, and visualization of complex clinical data drawn from patients across multiple healthcare institutions.
The approach outlined in this blog post can empower researchers anywhere in the world to access the resources they need to accelerate scientific discovery, clinical trial delivery, and improved care for children. With Amazon HealthLake, building a scalable, quick-to-deploy, FHIR-enabled health data platform to promote data interoperability and advanced analytics is now within reach for any healthcare organization or academic research center.